How Rittman Analytics Builds Data Stacks for Growth-Stage Businesses using Cube, Dagster and Preset
One of the new client case studies we published earlier this month was for our work with Osprey Charging Networks, one of the most-popular and fastest-growing EV charging networks in the UK and based not far from us in London, England.

As Lewis and I are both EV owners we know the value of a fast, reliable charging network and with Osprey planning to install over 800 new chargers in 2023, we’ve been working with their team to modernise and scale their data stack and data team to ensure it supports and powers Osprey’s growth over years to come.

In the past the choice of components for such a data stack would have been limited but as vendors such as Google Cloud (for Looker) and dbt Labs increasingly focus on enterprise, rather than growth businesses and as monolithic BI suites become increasingly disaggregated, we saw an opportunity to recommend a data stack architecture that was both best-of-breed and worked for startups in today’s more challenging funding environment.
Snowflake as the cloud data warehouse, a safe and easy choice
dbt Core (but not dbt Cloud) for data modeling and transformation
Dagster Cloud for data orchestration and data asset lineage
Cube Cloud for the semantic model, caching and role-based access
Preset Cloud, the commercial version of Superset, for dashboards and reports
Fivetran for data pipelines and other data ingestion
The Growth-Stage Modern Data Stack
The choice of vendors we recommended for Osprey Charging’s data stack is one example of the vendor partnerships and data stack component recommendations we’ve made this year for growth-stage organisations who we’ve found have broadly similar needs and goals:
A desire for a Looker-style dashboarding tool with an integrated business semantic layer
Data assets and a data architecture that extend beyond just batch SQL transformations updating warehouse tables on an hourly schedule
A budget for their data initiative that two years ago might well have been north of £250k — £500k but now is likely to be just half or a quarter of that, including spend on getting someone in like ourselves to get the first stage delivered
Generalised beyond just Osprey Charging and with further options such as Motherduck for the cloud data warehouse, Rudderstack for adding event collection, Airbyte for as an alternative to Fivetran for batch data extract and Estuary for ingesting data in real-time as well as services such as Rudderstack and Hightouch for data activation and reverse ETL, the diagram below shows the growth-stage data stack layers and services we generally recommend for clients today.
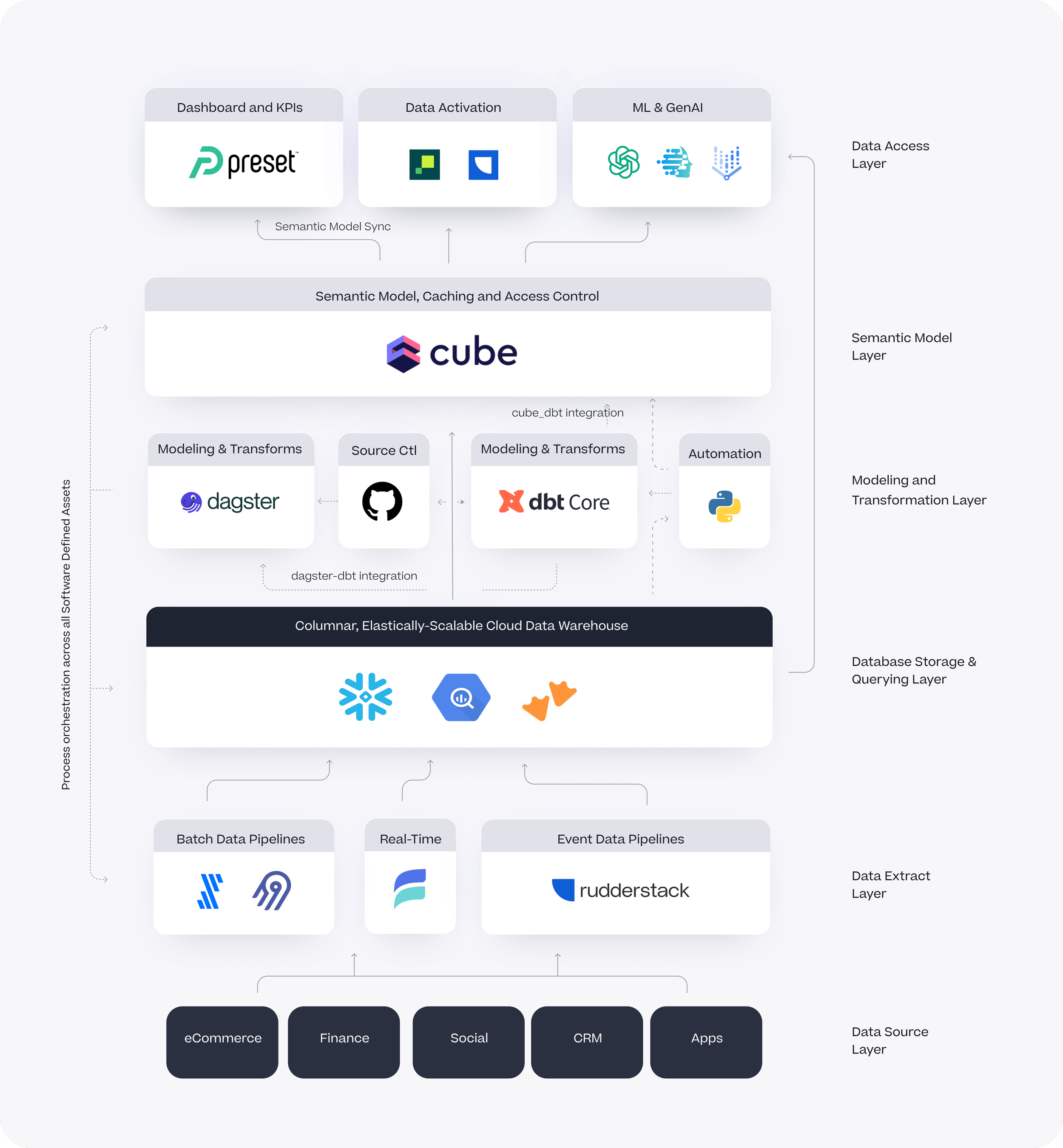
The Enabler: Cube, Dagster and Preset Integration
There have, of course, always been niche vendors within the modern data stack ecosystem but what makes this type of architecture increasingly viable is the integration between Cube, Dagster and Preset that’s now available as features provided by the commercial cloud-hosted versions of those products.
Cube, the disaggregated or “headless BI” semantic layer that also provides role-based access control and tools to pre-aggregate query results in your cloud data warehouse now comes with a Semantic Layer Sync feature in its cloud version that automatically creates, and then keeps in-sync, dataset definitions in tools such as Preset, Metabase and (coming soon) Power BI.

Another one of our clients, Breakthrough, was an early adopter of Cube’s Semantic Layer Sync and found value in having their BI tool work off the same semantic model as the data products that they embedded Cube into as their original use-case for their technology.

Both Cube and Dagster now have the ability to connect to dbt (via the dbt manifest file or via your dbt package’s git repository) to ingest model definitions and the entire dbt transformation DAG respectively into their own repositories, which coupled with Dagster’s ability to trigger builds of Cube pre-aggregations using Cube’s Orchestration API gives you a level of component integration as deep and in-fact wider than you had previously with Looker.

Preset is a great ad-hoc query tool and with this new, closer integration with Cube’s semantic layer the user experience is like Tableau connected to a Looker-style semantic model, something that’s possible now with Preset and Cube but still not available with actual Tableau and Looker Modeler at the time of writing despite being announced more than six months ago.

My colleagues Jordan Ilyat and Olivier Dupuis have a number of articles on Dagster including one on orchestrating Fivetran data extracts using Dagster and configuring Dagster to refresh data items in your warehouse based on freshness policies rather than a schedule, potentially saving you considerable running costs for your warehouse orchestration now that both Dagster and dbt Cloud have moved to consumption-based pricing.
The real advantage with Dagster comes when you have more than just dbt jobs to orchestrate to refresh data in your data stack, as in-fact most organisations do once you factor-in data extraction and data activation into your overall data architecture and as Olivier does in his Medium article.

How We Build Growth-Stage Data Stacks
Finally, if you’re interested in reading and hearing more about our approach to growth data stacks using Dagster, Cube and Preset then be sure to checkout two webinars on this topic that ran earlier this year:
“How Rittman Analytics Builds Modern Data Stacks using Cube, Preset and Dagster” where we cover all three tools along with a tool we use internally for automatically creating Cube metadata
“How Rittman Analytics delivers the semantic layer today with Cube” that we ran with Cube’s partner team that focused specifically on our Cube development process.
We still love Looker and as a Google Cloud Partner we’re super-excited to see Looker Modeler when it becomes generally available and in the meantime we’re evaluating the new Open SQL Interface for Looker that makes its semantic model accessible to other tools via its own JDBC driver.
But in the meantime there’s now an alternative in the form of Cube, Dagster and Preset that arguably has more features, is just as integrated and can cost a lot less to run — leaving you money in your budget to have us come in and do for your organisation what we did for Osprey Charging Network.
Interested? Find Out More!
Rittman Analytics is a boutique data analytics consultancy that works with growth-stage, mid-market and enterprise businesses in the UK, EU and North America who want to build and enable a data team based around a modular, scalable modern data stack.
We’re authorised delivery partners for Cube, Dagster, Preset, dbt Labs, Fivetran, Rudderstack and Snowflake along with Google Cloud (for Looker and Looker Studio), Oracle, Segment and Lightdash — we love them all and are experts at helping you choose the right ones for your organisation’s needs, use-cases and budget and working with you and your data team to successfully implement them.
If you’re looking for some help and assistance with your data project or would just like to talk shop and share ideas and thoughts on what’s going on in your organisation and the wider data analytics world, contact us now to organise a 100%-free, no-obligation call — we’d love to hear from you!