







Using Looker to Analyze and Visualise your Customer Concentration
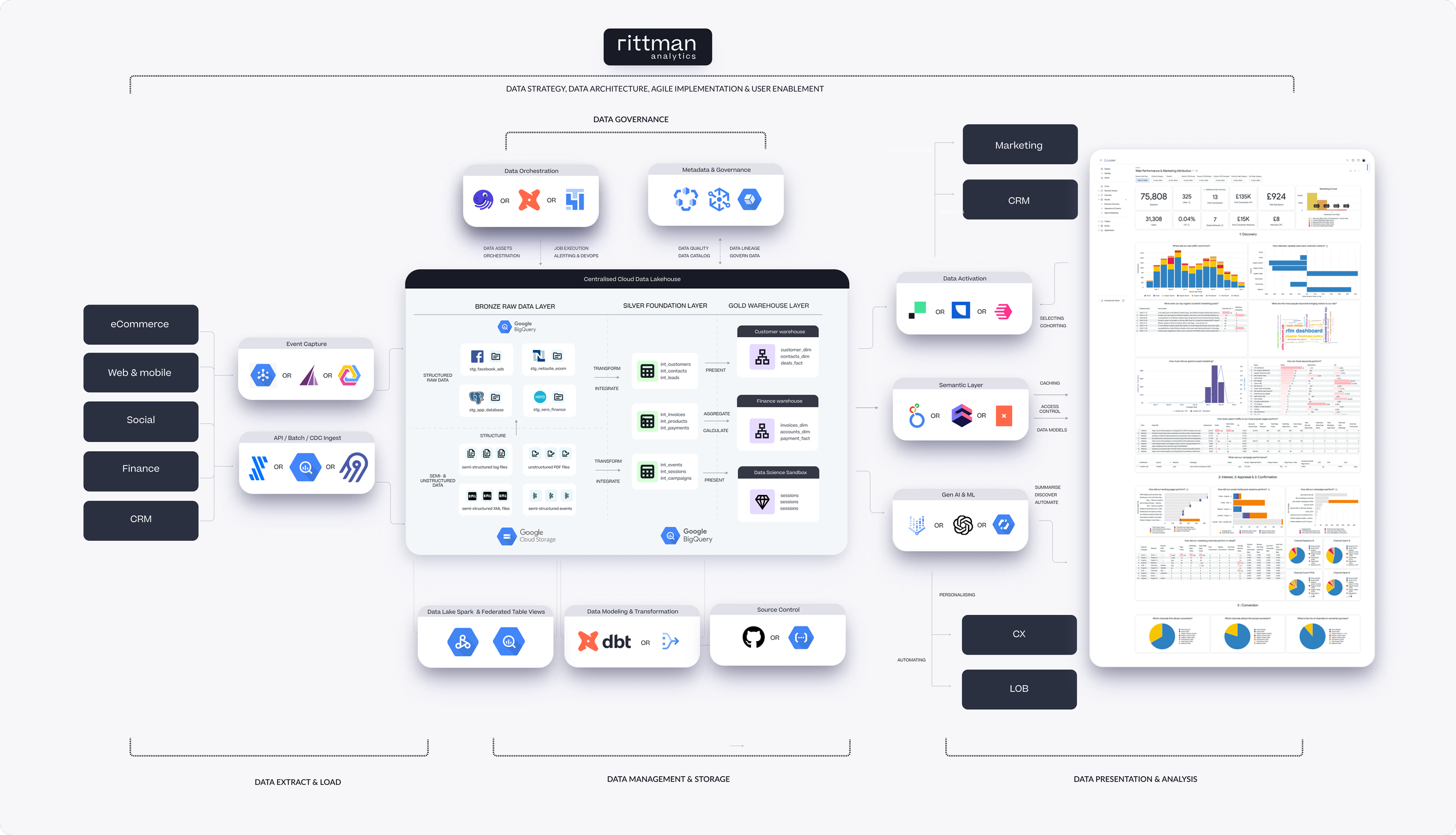
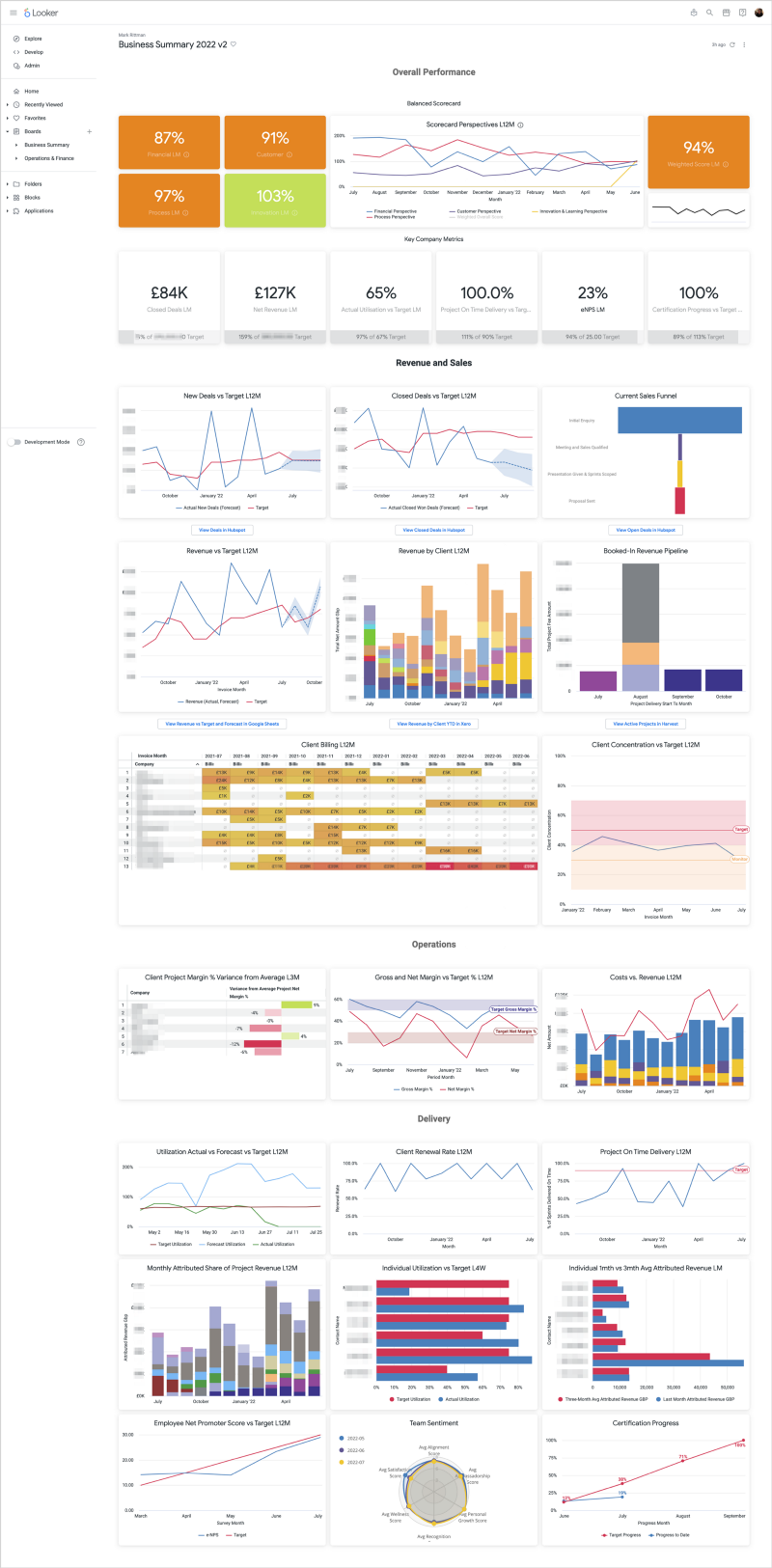
As a consultancy we monitor and visualize our customer concentration in the form of two data visualisations; one that shows our customer concentration curve and another that shows the trend of customer concentration for our business over time. In this blog I’ll explain how we do this using Looker, Google BigQuery and the modern data stack.
Adding Forecasting to your Looker Reports and Dashboards
A new feature introduced in Looker recently is Forecasting, giving you the ability to forecast forward one or more measures in your look or dashboard based on historical data in your application or data warehouse.
